Build A Receipt And Invoice Processing Pipeline with Amazon Textract
Overview
We receive countless receipts. Some of them matter more than others, and we treat them differently too. A lot of them (for example, those from grocery stores) are just thrown away almost immediately – at least that used to be my case.
Later I had the idea to start a side project to save all the receipts – hard or soft copies – store and index their metadata so that I can quickly lookup.
Technologies
Core Technology
Amazon Textract is the core technology I use to extract text from receipts and invoice and analyze different attributes, such as vendor name, invoice receipt date, total, tax, and individual items’ name, quantity and price (details can be found in the doc). It supports multiple file types: jpeg, png, and pdf (asynchronous only).
Other Supporting Technologies
Other AWS technologies I used include:
- Simple Email Service (SES): define a receiving rule to receive email with attachment and save it to a S3 bucket.
- Simple Storage Service (S3): store raw emails, attachments, and Textract analysis results. They are stored in 3 folders within the same bucket, but can also be done in 3 different buckets instead. The S3 bucket also has notifications enabled for object creation events that trigger Lambda functions. Structure is something like this:
/raw-emails//extracted/expenses/
/textract-analysis-results/
- Lambda: 3 Lambda functions to perform:
- extract attachments from raw emails and store them
- start Textract async analysis job
- get Textract analysis results
- Simple Notification Service (SNS): receive notifications when Textract async analysis job is complete, and trigger Lambda
- DynamoDB: store extracted receipt/invoice data
Design
High Level Diagram
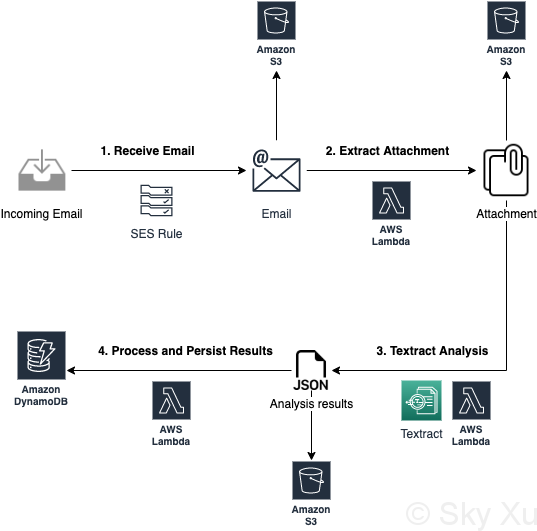
Detailed Diagram
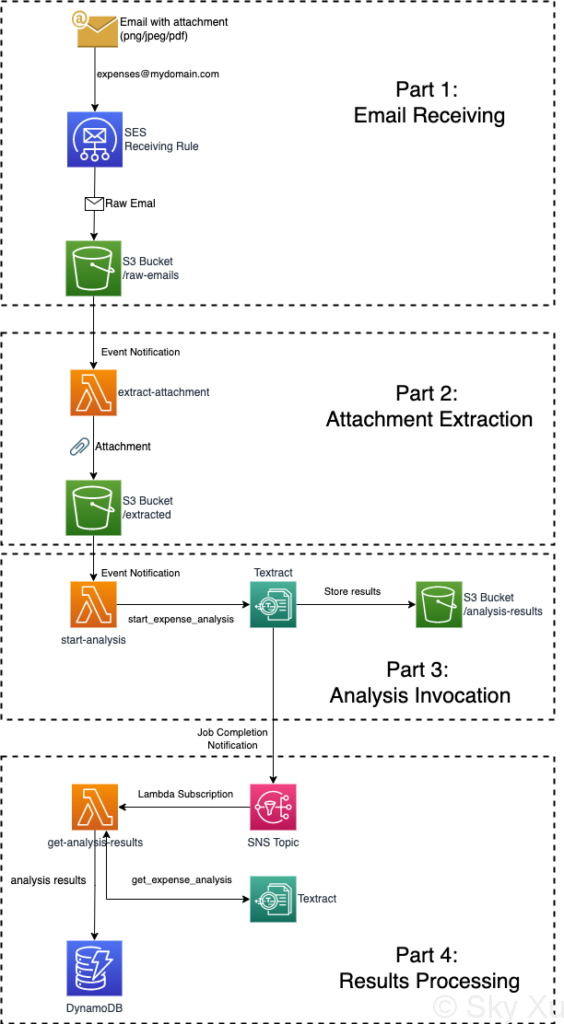
Detailed Workflow
1. Email Receiving
Steps:
- An email with attachment sent to a designated email address of my domain (e.g.
expenses@mydomain.com) - The email is picked up by the SES rule and is saved to S3 as raw email
It all started with an email with an attachment of receipt/invoice. It’s configured this way so that I can easily use my printer to scan a receipt and let it send directly to the designated email address.
For context, I have my own domain (e.g. mydomain.com), and have set up some receiving rules to forward received emails to my personal inbox. The rule set was like this:
- Bounce any spam
- Save email to S3, trigger Lambda to forward to my inbox. Recipient: all (i.e.)
mydomain.com
The new receiving rule that I add is targeted at the designated email address, i.e. expenses@mydomain.com. It is inserted before the last rule. Included actions are:
- Deliver to S3 bucket:
MyBucket. Object key prefix:raw-emails/. - Stop rule set.
2. Attachment Extraction
Steps:
- A raw email uploaded to
/raw-emails/inMyBucketS3 bucket (from previous step) - S3 event notification triggers the Lambda function
- The Lambda function read the raw email, extract the attachment and save it to another location
Add an event notification S3 bucket MyBucket for object creation events with object key prefix raw-emails/. The destination is a new Lambda function to extract attachment.
The Lambda function read from the S3 location of the raw email, extract the email, and put it to the /extracted/<folder>/. The reason I’m adding another level of sub-directory (i.e. <folder>) is that I’m planning to use /extracted directory for the files for other Textract analysis (for example, Analyzing Documents, or Analyzing Identity Documents). In this case, <folder> will be just expenses.
The Lambda execution role also need PutObject and GetObject permissions:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject"
],
"Resource": "arn:aws:s3:::MyBucket/*"
}
]
}Below is the sample Lambda code in Python 3.9 runtime:
# References:
# https://towardsdatascience.com/extract-email-attachment-using-aws-624614a2429b
# https://gist.github.com/sandeepmanchi/365bff15f2f395eeee45dd2d70e85e09
import json
import boto3
import email
import os
from datetime import datetime
import re
# a tuple of trusted sender address
ALLOWED_SENDERS = (...)
# File types that Textract supports
ALLOWED_CONTENT_TYPE = (
'image/png',
'image/jpeg',
'application/pdf'
)
MY_DOMAIN = '@mydomain.com'
def get_timestamp():
current = datetime.now()
return(str(current.year) + '-' + str(current.month) + '-' + str(current.day) + '-' + str(current.hour) + '-' + str(current.minute) + '-' + str(current.second))
def extract_attachment(message):
return message.get_payload()[1]
def check_sender(sender: str):
if sender in ALLOWED_SENDERS or sender.endswith(MY_DOMAIN):
return
raise Exception("Sender: [" + sender + "] not allowlisted!")
def check_content_type(content_type: str):
if content_type in ALLOWED_CONTENT_TYPE:
return
raise Exception("content_type: [" + content_type + "] not allowlisted!")
def lambda_handler(event, context):
# Event structure example: https://docs.aws.amazon.com/AmazonS3/latest/userguide/notification-content-structure.html
# print(event['Records'][0])
# Get current timestamp
timestamp = get_timestamp()
# Initiate boto3 client
s3 = boto3.client('s3')
bucket_name = event['Records'][0]['s3']['bucket']['name']
email_obj_key = event['Records'][0]['s3']['object']['key']
# Get s3 object contents based on bucket name and object key; in bytes and convert to string
data = s3.get_object(Bucket=bucket_name, Key=email_obj_key)
contents = data['Body'].read().decode("utf-8")
# Given the s3 object content is the ses email, get the message content and attachment using email package
msg = email.message_from_string(contents)
sender = re.search("<(.*@.*)>", msg['From']).group(1)
check_sender(sender)
recipient = re.search("<(.*@.*)>", msg['To']).group(1)
folder = re.search("(.*)" + MY_DOMAIN, recipient).group(1)
attachment = extract_attachment(msg)
attachment_content_type = attachment.get_content_type()
check_content_type(attachment_content_type)
attachment_name = attachment.get_param('name')
filename = timestamp + '-' + attachment_name
tmp_file_path = '/tmp/' + filename
destination_file_path = 'extracted/' + folder + '/' + filename
# Write the attachment to a temp location
open(tmp_file_path, 'wb').write(attachment.get_payload(decode=True))
# Upload the file at the temp location to destination s3 bucket and append timestamp to the filename
try:
s3.upload_file(tmp_file_path, bucket_name, destination_file_path)
print("Upload Successful")
except FileNotFoundError:
print("The file was not found")
# Clean up the file from temp location
os.remove(tmp_file_path)
return {
'statusCode': 200,
'body': json.dumps('SES Email received and processed!')
}
3. Analysis Invocation
Steps:
- Attachment created in S3 location (from previous step) and triggered Lambda function
- Lambda function pass the S3 location of the attachment, call Textract’s asynchronous
start_expense_analysisAPI. The API start the expense analysis job, and which returns Job ID - When the job is complete, a notification is sent to an SNS topic with Job ID.
Similar with previous step, when the extracted attachment is created in S3, the event notification triggers another Lambda function, which invokes Textract’s asynchronous start_expense_analysis API. The Lambda execution role also requires:
GetObjectpermission toarn:aws:s3:::MyBucket/*– this is needed to get the attachment locationPutObjectpermission toarn:aws:s3:::MyBucket/textract-analysis-results/*– this is needed ifOutputConfigparameter is specified to this.AmazonTextractFullAccess(Amazon managed policy) – needed to invoke asynchronous analysis
An SNS topic need to be created and configured to receive the Textract job notification. The ARN of SNS topic and role are required to be passed into the NotificationChannel option.
Sample code – note that I wrote it in Ruby 2.7 runtime, because I found that the native boto3 version of the Python runtime does not have start_expense_analysis API yet (as of this writing).
require 'json'
require 'aws-sdk-textract'
def lambda_handler(event:, context:)
puts event
# Get the object from the event and show its content type
bucket = event['Records'][0]['s3']['bucket']['name']
key = event['Records'][0]['s3']['object']['key']
folder = key.match("^extracted/(.*)/").captures[0]
# Can be extended with different types based on folder value
response = start_expense_analysis(bucket, key) if folder == 'expenses'
puts(response)
return response[:job_id]
end
def textract_client
@textract_client ||= Aws::Textract::Client.new
end
def start_expense_analysis(bucket, key)
textract_client.start_expense_analysis({
document_location: { # required
s3_object: {
bucket: bucket,
name: key
},
},
job_tag: 'expense',
notification_channel: {
sns_topic_arn: 'arn:aws:sns:[REGION]:[ACCOUNT_ID]:[SNS_TOPIC]', # required
role_arn: 'arn:aws:iam::[ACCOUNT_ID]:role/[SNS_ROLE]' # required
},
output_config: {
s3_bucket: bucket,
s3_prefix: 'textract-analysis-results',
}
})
end4. Results Processing
Steps:
- When the job is complete, a notification is sent to an SNS topic with Job ID (from previous step)
- Subscriber Lambda function triggered by SNS notification
- Lambda call Textract’s
get_expense_analysisAPI with Job ID, and get results - Lambda process results data and save to DynamoDB table
Create a Lambda function and subscribe to the SNS topic. When it gets the Job ID from the SNS notification, it calls get_expense_analysis to obtain analysis results. The results contains a lot more data than what I’m interested in, so I only store a subset of the data. For the standard fields that AnalyzeExpense currently supports, see AWS Textract documentation.
On DDB side, I use job_id as partition key. The job ID itself is meaningless, so all my queries depend on Global Secondary Indices (GSI) – the only field that I care about is the vendor_name, so I created index on that. Besides these data returned from Textract, I also store the S3 location of the attachment file.
Sample DDB item:
{
"job_id": "7b8dbc3495034cbc74b679f7856a8292707d0d68fa3bc0305dfdc8a3d36c1cc4",
"timestamp": 1647817393374,
"document_location": {
"S3Bucket": "MyBucket",
"S3ObjectName": "extracted/expenses/receipt_name.jpg"
},
"invoice_receipt_id": "123456789",
"subtotal": "67.43",
"tax": "1.21",
"total": "68.64",
"vendor_name": "COSTCO WHOLESALE"
}The Lambda execution role also need:
AmazonTextractFullAccess(Amazon managed policy) – needed to get analysis resultsGetObjectpermission toarn:aws:s3:::MyBucket/textract-analysis-results/*– this is needed to obtain analysis results from where it’s storedPutItempermission to the DDB table
Sample Lambda code:
require 'json'
require 'aws-sdk-textract'
require 'aws-sdk-dynamodb'
# Avalable types: https://docs.aws.amazon.com/textract/latest/dg/invoices-receipts.html
TYPES = %w[VENDOR_NAME TOTAL RECEIVER_ADDRESS INVOICE_RECEIPT_DATE INVOICE_RECEIPT_ID PAYMENT_TERMS SUBTOTAL DUE_DATE TAX TAX_PAYER_ID ITEM_NAME]
def lambda_handler(event:, context:)
# puts event
message_string = event['Records'][0]['Sns']['Message']
message = JSON.parse(message_string)
job_status = message['Status']
unless job_status == 'SUCCEEDED'
raise "Job status: #{job_status} not SUCCEEDED!"
end
job_tag = message['JobTag']
job_id = message['JobId']
job_timestamp = message['Timestamp']
document_location = message['DocumentLocation']
method_name = "get_#{job_tag}_analysis_results"
results = self.public_send(method_name, job_id)
item = {
job_id: job_id,
timestamp: job_timestamp,
document_location: document_location,
# analysis_results: results
}
expense_documents = results[:expense_documents]
expense_documents.each do |doc|
summary_fields = doc.dig(:summary_fields).each do |field|
type = field.dig(:type, :text)
next unless TYPES.include?(type)
item[type.downcase.to_sym] = field.dig(:value_detection, :text)
end
end
request = {
table_name: 'ExpenseSummary',
return_consumed_capacity: 'TOTAL',
item: item
}
# https://docs.aws.amazon.com/sdk-for-ruby/v3/api/Aws/DynamoDB/Client.html#put_item-instance_method
response = ddb_client.put_item(request)
response
end
def get_expense_analysis_results(job_id)
# https://docs.aws.amazon.com/sdk-for-ruby/v3/api/Aws/Textract/Client.html#get_expense_analysis-instance_method
textract_client.get_expense_analysis({
job_id: job_id
})
end
def get_document_analysis_results(job_id)
# Data storage not ready yet
raise NotImplementedError
# https://docs.aws.amazon.com/sdk-for-ruby/v3/api/Aws/Textract/Client.html#get_document_analysis-instance_method
# textract_client.get_document_analysis({
# job_id: job_id
# })
end
def textract_client
@textract_client ||= Aws::Textract::Client.new
end
def ddb_client
@ddb_client ||= Aws::DynamoDB::Client.new
endPossible Extensions
- Data
- store more detailed per-item data
- vend data
- Workflow
- for scaling purpose, add SQS queue before Lambda to receive notification, instead of invoke Lambda directly
- add human review process to improve precision for lower confidence score
- Functionality
- process more attachments in single email
- email notification when the process succeeded or failed
- Use Cases
- use the similar processing pipeline to analyze and process documents or identity documents.
References
- Tutorials
- AWS Textract Documentations
- AWS SDK API References
- Textract (Ruby):
- DynamoDB (Ruby):
- S3 (Python Boto3):